书籍外文名:Mastering Web Application Development with AngularJS
现已迁移至:这里
今天开始,我会陆续对这本书的部分章节(也许是全部)进行翻译,不包括前言等。翻译说明:
- 对于诸如
directives这样的术语不做翻译 - 不全段翻译,有可能删去废话段落进行翻译
- 翻译属于边看边学边敲代码的过程,可能会加入自己的注解
这本书的主要能够学到以下三点:
- 如何利用目前已有的AngularJS的
services和directives构建一个完整且健壮的应用 - 在没有现成的解决方案时如何扩展AngularJS
- 如何建立一个高质量的AngularJS开发项目(类似于种子):包括代码组织、项目建立、测试、性能优化等
学习过程中,你需要准备如下开发环境/工具:
- web浏览器 + 文本编辑器 / IDE
- 安装node.js及其包管理工具npm
- Grunt + Karma
- 后端是跑在MongoDB上的(需要网络)
Ch.1 AngularJS之道
前面是一堆废话说angular(以下用angular代称angularJS)将来会很好,blabla,此处省略几百字。接下来讲下这章的内容:
- 如何用些angular版本的hello world
- angular应用的基本组成部分:directives, scopes, controllers
- angular的依赖注入
- angular和别的框架或库(尤其是jQuery)的差别
angular框架概览
angular特殊在于它的模版系统(templating system):
- 用HTML作为模版语言
- 因为angular可以跟踪用户操作,浏览器事件以及model改变,所以不需要显式地DOM更新,它会找出什么时候哪个模版需要更新
- angular对HTML标签及属性进行了扩展,所以它能告诉浏览器去解析这些扩展
angular别的隐藏大招如:DI(依赖注入)、测试
angular大杂烩
主要就是讲一些这个项目的起源,以及在github上开源,还有Google+以及别的社区上(如StackOverflow)可以获得的帮助。此处不翻。
很多东西你都可以在angular官网上找到,虽然我觉得里面的文档写得很shi。另外推荐一个国内的关于angular资料整理的很好的链接:AngularJS资源大集锦。
至于基于angular写的很多插件、库和扩展,可以到这个网站上找到。
一些工具:
- 传统工具:IDE如webstorm, sublime text
- angular团队贡献的:Batarang, Plunker, jsFiddle
angular的hello-world
要是真像标题所说的有crash course这样逆天的存在,真的就不用学了,angular的学习曲线很陡,这是个人经验。
通过hello-world例子学习angular基础组成部分:
首先直接看以下hello-world的代码:
<html>
<head>
<script src="http://ajax.googleapis.com/ajax/libs/angularjs/1.0.7/angular.js"></script>
</head>
<body ng-app ng-init="name = 'world'">
<h1>Hello, { {name} }!</h1>
</body>
</html>
- 在项目页中引入angular库:1)通过google的CDN;2)也可以下载下来
- 引用了库之后,就是在你的应用里如何启用angular了,通过:
ng-app这个HTML属性 - 在body标签中还有一个非标准的HTML属性:
ng-init,这个属性可以让你在模版被渲染之前准备好数据模型 - 最后需要介绍的是 {{name}} 这个表达式,它做的工作很直接,直接将
ng-init准备好的数据模型里的值渲染输出
从以上的示例我们可以看出,angular模版系统的两个特点:
- angular使用自定义HTML标签和属性来为静态的HTML页添加动态行为
- 双大括号({{表达式}})被用来让表达式输出数据模型的值
directives:
从上面的示例我们首先要引出的第一个angular的关键术语:directives,它是指所有angular这个框架能够理解并解析的特殊的(非标准的)HTML标签和属性。
双向绑定:
从示例我们要讲的第二个关键术语就是:双向数据绑定。从 ng-init 我们可以看到准备好的数据模型是可以通过双大括号包含表达式的方式渲染出来值的。如果在此基础上我们引入 ng-model的话,那么angular就可以做到:
- 实时检测到数据模型的变化,而在下面这个例子中的数据模型的变化又恰恰是由视图的变化引起的;
- 根据数据模型值的变化对模版(也就是DOM)进行实时更新。
也就是说,angular为我们省去了那些多余的为了让模版进行更新而所需的DOM操作。代码如下:
<body ng-app ng-init="name = 'World'">
Say hello to: <input type="text" ng-model="name">
<h1>Hello, { {name} }!</h1>
</body>
其实从上述代码不难发现,所谓的双向绑定,实质上涉及的是两种对象,三个实例:
- 数据模型对象(一个实例):
name - 模版对象/视图对象(两个实例):一个是
<input>(视图对象),另一个是 {{name}} (模版对象);而模版对象其实是可以看作是视图对象的一部分,只不过它特殊一些,会动态变化,因为模版是和数据模型绑定的
所以上述的数据绑定过程其实很简单,发生在三个对象实例之间,关键是全部都是实时的,大概是这样:
<input>接收用户的实时输入,实时改变数据模型name- name的实时改变直接引起了模版对象{{name}}的渲染输出结果,并最终影响了
<h1>中的渲染结果
angular中的MVC模式
现在市面上的web-app大多数都是基于某种MVC模式或其变式。但是MVC的问题在于它不是一个很精确的模式,相反它是一个相对顶层的设计,属于架构层次的。而基于MVC而衍生的变种也很多,如MVP、MVVM是属于大众人气比较高的。记住一点,不同的开发团队,他们理解的MVC模式是不尽相同的。这一点,Martin Fowler在这篇文章里进行了总结。
麻雀虽小,当应五脏俱全
之前hello-world的例子中把数据模型初始化、逻辑和视图混在一个文件中,这是典型的没有展现分层的策略。那如果要把angular团队强调的MVW模式引入进来,那么这个例子要如何重写呢(以后书中所有代码均略去初始化及脚步包含部分)?
<div ng-controller="HelloCtlr">
Say hello to: <input type="text" ng-model="name"><br>
<h1>Hello, { {name} }!</h1>
</div>
我们移除了 ng-init 属性,取而代之的是一个指向了一个js函数的 ng-controller 指令,它的代码如下:
var HelloCtrl = function ($scope) {
$scope.name = "World";
}
逻辑很简单,就是把原来通过 ng-init 准备的数据模型 name 现在我们用另外一个指令来完成,这个指令就是 ng-controller ,它是通过往 $scope 对象中添加属性的方式来准备好我们需要的数据模型。也就是说,现在我们的数据模型都存放到了 $scope 对象之中了,那么这个对象又是何方神圣呢?
$scope对象基础
关于 $scope 对象的几点:
$scope对象负责把数据模型对象(集)暴露给模版对象/视图对象- 为
$scope对象增加属性可以是数据,也可以是函数操作,但是它们都是有具体的视图对象范围的,也就是说我们可以通过一个$scope对象实例将具体的UI操作逻辑暴露给模版对象 $scope对象允许我们可以精确地控制整个对象的哪些部分是可以从视图/模版中获取到的(如以下的getName)
上面的 HelloCtrl 可以新增加一个 getter 函数用来取name值,这样就可以把name值当作私有属性而不直接暴露在视图对象中了,代码如下:
var HelloCtrl = function ($scope) {
$scope.name = "World";
$scope.getName = function() {
return $scope.name;
}
}
然后就可以在模版中使用这个getter了:
<h1>Hello, { {getName()} }!</h1>
controller
上面我们讲是通过 ng-controller 替代了 ng-init 来进行数据模型的准备,而这就是angular中的又一重要组成部分:controller,也就是控制器。它的首要任务就是初始化 $scope 对象,进而为储存数据模型对象集做准备。而这个初始化过程又主要包括这两个任务:
- 提供初始化数据模型值
- 用具体的UI操作逻辑(即函数)来扩展
$scope对象
controller(控制器),说到底其实就是普通的js函数。它的运转是无需扩展特定的框架类或是调用angular的APIs。另外,就如我前面所说,ng-controller 无非就是用js的方式来表达了 ng-init 这样一个过程,而且避免了将初始化逻辑(这里是数据模型)与HTML模版混杂。
model
Model(模型)就是普通的js对象。通过上一节中介绍的controller初始化的两个任务,其实可以看到,它们就是MVC架构中的Model(模型)的两个重要部分:
- 数据模型(私有数据)
- UI操作逻辑(公有函数)
最后Model通过暴露自己的UI操作逻辑来实现封装数据,使用安全。
而Model,说白了,就是被当作属性添加到 $scope对象上的,这样就能暴露给模版对象了。
$scope对象进阶
通过以上各小节从:$scope 对象基础 --> controller --> model 这样的流程,我们可以来更深地学习一下这个对象。首先我们必须明确一点: $scope 对象是 Scope 类的一个实例。而 Scope 类拥有诸多方法如控制着它的实例的生命周期,提供事件传播机制,以及支持模版渲染进程。
scopes的层次
重新看一遍 HelloCtrl 的代码,与普通js的构造函数没有什么区别,只有唯一的一个值得注意的地方就是函数参数 $scope,那么这个参数是哪里来的呢?这就牵扯到 $scope 对象的生命周期了:
- 首先一个新的scope可以通过
ng-controller指令通过调用Scope.$new()函数来创建的 - 能够调用上述方法的前提是我们拥有一个scope的实例,angular中有:
$rootScope,这个对象是整个应用其他scopes的父亲,它在应用启动时被创建 - scopes形成了一个以
$rootScope为根节点父子节点组成的树状图,这和DOM树是一致的,也就是说scopes中的各个scope是在对应着DOM结构
能够创建scopes的指令
ng-controller 是其中一个可以可以创建scope的指令,其他还有很多类似的创建scope的指令。angular在扫描DOM树时每遇到一个这样可以创建scope的指令的时候,都会创建一个 Scope 的实例。新创建的scope都有一个 $parent 属性指向它们的父级scope。
现在来看另一个能够创建子级scope的指令:ng-repeat
// the controller
var WorldCtrl = function ($scope) {
$scope.population = 7000;
$scope.countries = [
{name: 'France', population: 63.1},
{name: 'United Kingdom', population: 61.8}
];
};
// the markup fragment
<ul ng-controller="WorldCtrl">
<li ng-repeat="country in countries">
{ {country.name} } has a population of { {country.population} }
</li>
<hr>
World's population: { {population} } millions
</ul>
ng-repeat 创建了两个新的scope,在视图中,也就对应着两个新的<li>,在Chrome中你可以通过Batarang插件看的一清二楚。ng-repeat 中指定的新的变量 country 成为了新的两个子级scope中的数据。这时候你会看到两个 <li> 它们对应的scope中有重名函数,但这不会导致命名冲突,因为**每个 <li> 拥有它自己的scope也就有它自己的命名空间。
scopes的继承
定义在高层scope中的属性是可以被其子级scopes继承,因为angular规定:子级scope不重新定义父级scope中已有的属性。以上面的国家人口例子为开始,现在我们想要显示各个国家占全球总人口的百分比,那么在父级scope(也就是ng-controller创建的scope,对应模版中的<ul>)定义一个计算百分比的逻辑,那么在两个<li>中均可以调用到该函数(可以理解为继承了),而不用分别在两个<li>中做冗余的函数定义了,代码如下:
// the controller
var WorldCtrl = function ($scope) {
$scope.population = 7000;
$scope.countries = [
{name: 'France', population: 63.1},
{name: 'United Kingdom', population: 61.8}
];
$scope.worldsPercentage = function (countryPopulation) {
return (countryPopulation / $scope.population) * 100;
}
};
// the markup fragment
<ul ng-controller="WorldCtrl">
<li ng-repeat="country in countries">
{ {country.name} } has a population of { {country.population} },
{ {worldsPercentage(country.population)} } % of the World's population
</li>
<hr>
World's population: { {population} } millions
</ul>
总结来讲,angular中的scope的继承遵循js的原型继承的相关规则(也就是说当我们试着读取一个属性时,原型链机制启用,一层层往上直到这个属性找到)。
scopes继承的潜在危险
scopes的继承机制在读属性这个操作时没有问题简单易懂,而在写属性时,事情就变得十分复杂。还是拿hello-world的那个例子来看:
// the markup fragment
<body ng-app ng-init="name='World'">
<h1>Hello, { {name} } </h1>
<div ng-controller="HelloCtrl">
Say hello to: <input type="text" ng-model="name">
<h2>Hello, { {name}} !</h2>
</div>
// the controller
var HelloCtrl = function ($scope) {
};
运行如上代码首次加载时,都是出现 Hello, World!,但是在用户通过<input>进行输入之后,<h2>中的显示改变了,跟随用户输入而变,这是因为 ng-controller 创建了子级的scope,虽然 HelloCtrl 什么初始化也没有做。
上面的例子中,用户输入通过 ng-model 进行了scope上面的name属性的重写,但是幸运的是,只影响到了我们事先想要影响的模版/视图区域。那这里有没有可能影响到 <h1>中的模版对象呢?答案是有的。如下,将 ng-model的引用指向父级scope中的name属性即可:
<input type="text" ng-model="$parent.name">
虽然通过上面的方法,视图中三个使用了{{name}}模版的区域都得到了同步的更新,但是这个解决方案毕竟是脆弱的。因为通过 ng-model 这样的方法是建立在对于全局的DOM结构的假设的基础上的,如果在<input>上动态地添加了一个新的DOM节点,那么上面的 $parent 就会指向这个动态添加的(之前未曾料想到的)的节点,那么就会出现意料之外的效果。所以,**尽量减少使用 $parent 是王道呀。
那么既然上面的方法行不通,有没有什么别的方法可行呢?答案还是:有的。那就是让 ng-model 绑定到的变量是一个对象的属性,也就是说之前绑定的变量name是直接裸露在 $scope 的第一层,也就是 $scope.name ,那么这时候我们通过把 name存成对象的属性的形式,这样就可以大大提高安全性,而且达到目标效果。
<body ng-app ng-init="thing = {name : 'World'}">
<h1>Hello, { {thing.name} }</h1>
<div ng-controller="HelloCtrl">
Say hello to: <input type="text" ng-model="thing.name">
<h2>Hello, { {thing.name} }!</h2>
</div>
</body>
以上原则是angular提倡的,即:避免直接绑定到scope的属性,多加一层,绑定到scope的属性的属性是更好的方法。
scopes领衔的事件系统
scopes的组织架构(层次)图可以当作一辆bus来运载angular中的事件,那么也就有了事件bus。angular允许我们远着scope的层次传递自定义姓名的事件,可以往上($emit),也可以往下($broadcast)。
angular中的两大组成部分 services 和 directives 就是利用这个事件bus在应用中发送全局状态改变的消息。比如,我们可以监听从 $rootScope 广播出的 $locationChangeSuccess 事件,这样就可以知道URL是否改变,好做出相应的策略。
$scope.$on("$locationChangeSuccess", function(event, newUrl, oldUrl) {
// react on the location change here
// for example, update breadcrumbs based on the newUrl
})
关于事件的几个注意点:
$on方法是每个scope实例对象都可以调用的,并且为其注册一个事件处理器。这个事件处理器可以有三个参数,第一个是发起的事件,第二个和第三个是视具体的事件发出的消息而定- 可以通过
$emit或$broadcast发出事件 - 与传统的DOM事件一样,也可以使用
preventDefault()和stopPropagation()方法作用于事件对象上。stopPropagation()能阻止事件沿着scope层向上冒泡,但是它只对那些通过$emit发起的事件有效 - 除了以上两个函数一样,angular的事件机制和DOM事件机制完全是两个独立的个体,没有交集
- 在你确定想要使用自定义事件时,一定要斟酌再三,因为在angular里常常通过双向数据绑定就可以解决问题了
- angular中的内置事件:
- $emit: $includeContentRequested, $includeContentLoaded, $viewContentLoaded
$broadcast: $locationChangeStart, $locationChangeSuccess, $routeUpdate, $routeChangeStart, $routeChangeSuccess, $routeChangeError, $destroy
scopes的生命周期
scopes是用来提供独立的命名空间和避免变量名冲突的。scopes是有生命周期的,当其不再被需要时,可以被摧毁,这样通过scopes暴露的数据模型和UI操作逻辑也就可以被回收。
正如 directives 那一节所讲的,scopes通常是经过可以创建scope的指令进行创建,当然摧毁也一样。你也可以通过 Scope.$new() 和 Scope.$destroy() 这两个方法人工进行scopes的创建和摧毁。
View
前面讲述了MVC模式中的Controller和Model,而且重点介绍了angular中用来暴露Model的 $scope 对象。接下来讲讲View,也就是视图对象。angular视图有如下几个特点:
- angular中的模版语言是HTML(视图可以看作是各种模版拼接起来的一个大模版)
- angular中的HTML语法是允许扩展的
- angular中的模版是允许局部更新的,而且这种局部更新完全是数据模型驱动的自动更新,无须手动干预
- angular应用的视图渲染过程分三步:
- 浏览器解析各个模版块中的文本及标准的HTML标签,生成DOM树
- DOM树生成后angular杀进来遍历这个已经被解析好的DOM结构
- 每当angular遇到一个directive,它就执行这个directive(指令)的逻辑将其动态地渲染成视图的一部分输出到屏幕
声明式模版
angular提倡声明式的方法来进行UI的构建。它意味着在实践中模版把焦点放在叙述出一个UI效果而非去关注如何实现这个效果上。也就是说,模版重点体现想要达到的视图效果,而背后实现的逻辑则是交给controller去完成。
书上的一个例子,罗里吧嗦一堆,其实就是个微博输入框的例子,字数限制,到最后几个字给提示,超过字数不给发送的一个 <textarea> 的表单。先看下第一个版本的实现代码:
// the markup fragment
<div><span>Remaining: { {remaining()} }</span></div>
<div class="container" ng-controller="TextAreaWithLimitCtrl">
<div class="row">
<textarea ng-model="message">{ {message} }</textarea>
</div>
<div class="row">
<button ng-click="send()">Send</button>
<button ng-click="clear()">Clear</button>
</div>
</div>
// the controller
var TextAreaWithLimitCtrl = function ($scope) {
$scope.message = "";
$scope.remaining = function () {
return MAX_LEN - $scope.message.length;
}
$scope.hasValidLength = function() {
if ($scope.message.length <= MAX_LEN)
return true;
}
}
基本版本完成,记住:ng-model 不能完成数据准备,它赋值的右端的那个变量也需要通过在 ng-init 或者controller里面准备好。接下来是要将发送按钮失活,代码如下:
<button ng-disabled="!hasValidLength()" ng-click="send()">Send</button>
通过以上代码中 remaining() 和 hasValidLength() 的使用我们可以看出,要去进行UI操作,我们只需要去动模版中的一小部分,直接通过指令去描述一个想要的效果,这也就更加证实了angular的模版更关注描述效果,而把关注效果实现的部分丢到后面去解决。虽然我们在HTML标签中嵌入了代码,但是这个代码和js代码的耦合是隐式的,是通过注册在scope下的数据模型进行连接的,但是在实际的js代码维护中,我们完全不用去自己建立指向DOM元素的引用以及直接操作DOM,这样就在js代码中省去了很多麻烦。以上两个方法的状态变化,都源自数据模型 message 的值的变化,进而影响UI中的效果。接下来的一个数字倒数的显示效果的操作也是一样(代码在第一版本基础上进行修改):
<div><span ng-class="{'text-warning' : shouldWarn()}">Remaining: {\{remaining()}\}</span></div>
// code should be added to TextAreaWithLimitCtrl
$scope.shouldWarn = function () {
return $scope.remaining() < WARN_THRESHOLD;
}
ng-class 是能够直接改变css类选择器的,那么上面的代码直接可以看出:
message 影响 remaining() 影响 shouldWarn() 影响 ng-class 最终影响 UI效果
在上述过程中,这个 <span> 新添加了css类 text-warning 以至于UI重绘,但是整个过程在 TextAreaWithLimitCtrl 的js代码中完全没有见到DOM操作。如果用户或是代码协作者看这个模版和controller的话,完全就可以理解为:“哇操,太牛B了,在HTML中说了一声‘我想要得到警告提示’,然后UI就重新绘制了,而且js代码中完全没有对DOM元素的操作,擦嘞,angular太牛了,直接把这部分工作给我做了”。
场景比较
- 有ng-class:我们是通过它说
text-warning这个css类需要被加到<span>中,这样每次用户输入字符时就会有警告提示 - 无ng-class:也就是传统的实现方式,不用angular的情况。我们是这样做的,当用户输入一个字符了,而且总的字符数超出限制了,那好,我想找到那个用来做提示的
<span>标签,然后给它加上一个css类叫text-warning,然后做出相应的显示
可以看到,上述两种场景是用angular(1)和不用angular(2)的区别。显然它们几乎是一个相反的过程。
- 用到angular的场景1相当于自动已经在
<span>上安装了一个陷阱,等着用户输入触发的事件往里跳,DOM操作都交给angular了,我们只要关注想要什么效果,然后说一声“我们想要有警告提示”,然后就有警告提示了。 - 而没有用angular的场景2,则是要每次都要去找到那个
<span>,然后给它加css类,然后改变显示,相当于一心二用,既要关心要加的效果,又要关心效果怎么加上去(即取到那个DOM元素的操作),而后一步,就是多出来的DOM操作的逻辑,在js代码中这样就会显得没有angular来的利索。
如果用专业术语来讲:场景1就是所谓的declarative approach,而场景2则是所谓的imperative approach。显然,场景1仿佛就只要说一句话,效果就分分钟的事,就好像是在说:“亲爱的angular先生,当我的数据模型以xxx状态结束时,我想让我的UI看起来像这个样子。所以现在你去给我搞定它,怎么搞/何时搞我可不管。就这么简单。”
显然,场景1(声明式编程)显得更具语义化且更具表现力,它使程序员可以摆脱去写大量重复的且需要复杂控制的更底层的指令和代码。声明式编程最后的代码非常简洁,而且易读。当然,这就需要有能够正确解析这些更高层的指令(来自声明式)的机制,这里,angular就是这样的机制。
另外,场景2(命令式编程)也有它自己的优点,那就是可以控制全局而且在微调和优化上更容易操作。虽然获得了更高的控制权,但是代价也是巨大的,那就是写一大堆底层的重复的代码。
其实,熟悉SQL的人也知道,它也是一种声明式编程。就是简单声明一个我想要的结果,然后让数据库去搞定给我送回来,就是这么简单。
angular模版中的指令声明式地表达自己想要的效果,这样我们就可以从一步一步地写具体的DOM操作指令中解放出来。而jQuery恰恰相反,它正是那种去一步步进行DOM操作,一个属性一个属性的去修改DOM元素上的属性,最后达到想要的效果。
需要注意的是:angular虽然在模版编程中大力提倡使用声明式的,但是在js代码中,它提倡的命令式编程,这就包括用命令式一步步去完成controller和业务逻辑的代码(但肯定不包括DOM操作)。当然,唯一的特例,也就是说在代码中能有DOM操作的就是在directives中。但是无论何时,永远不要在controller中进行DOM操作。当然,我们需要明白和理解angular底层是如何去完成这些我们交给他们的操作的,这样我们能在遇到性能问题的时候,能够给angular更多的提示和解决方案。
angular的modules
机智如我,早已发现之前的几个例子全是在全局下定义controller。但咱都知道滴,全局状态不可以多用呀,必然杀敌一千,自损八百呀,有木有。它不仅伤害到了应用的结构,让代码更难维护、测试、阅读,更重要的是苦了程序猿。angular中,提供了一系列API用来定义模块(modules)并且让我们可以在模块上注册(添加)各种各样的对象。
angular.module()
让我们把之前的HelloCtrl变下形看看:
angular.module("hello", [])
.controller("HelloCtrl", function($scope) {
$scope.name = "World";
})
从上面短短的几行代码我们来分析看看:
- angular本身定义了一个全局的命名空间,就叫
angular - 在
angular这个命名空间下游很多实用工具和函数 module就是angular中的一个函数,它的主要作用是作为angular其他对象(如controllers,services等)的一个容器,可以理解为二级命名空间。定义一个module需要两个参数,第一个作为module的名字,第二个则是指出这个module都依赖哪些别的modulesangular.module()方法的调用返回一个新创建的module实例,而我们定义控制器就是在这个返回的实例中进行的- 在返回的module实例中直接调用其
controller()方法,提供两个参数:一个是控制器名,另一个则是构造函数
经过以上,一个定义了控制器的module就准备好了,那么要怎么告诉具体的HTML页我这个页用的是哪个module呢?答案如下:
<body ng-app="hello">
这里,你可以将ng-app理解为它是使整个angular应用启动的指令,同时也声明了命名空间。
angular的依赖注入
我们很早之前就把$scope当作controller中的构造函数的参数进行使用了,但是到底是什么机制可以那么神奇地让我们在没有任何地方定义到这个东西,但是却可以使用呢?之前也讲过,ng-controller时就触发了Scope.$new创建了一个新的scope实例,但是它是怎么被塞进来的呢?因为从头到尾,我们其实就只做了一件事:“要让我的函数正常运行,我需要依赖$scope,所以,angular,给我搞一个来,不管你怎么弄。”
通过上面简短的介绍,之所以我们能够获得想要的依赖(即:协作对象),是因为angular内置了依赖注入引擎,它可以实现下面的操作:
- 知悉某个对象有对别的协作对象的依赖的需求
- 找到需要的协作对象
- 将发起需求的对象和协作对象绑到一块组成一个具有完整功能的应用
以上几点基本展示了声明式表达依赖的作用,它可以让各个协作对象不用去考虑其他对象的生命周期,有时候进行一些swap,替换等,又可以创造新的应用了,而且这也是angular能高效完成单元测试的原因。(以上这句感觉跟扯淡似的,也许是因为还没理解到精髓)。
DI的好处
这一小节事实上写了个小demo,讲推送消息的,如何用好DI,现在还不太理解,只好先作罢,不翻。 to be continued ...
angular的services
上一节的讲的内容是我觉得到目前为止这本书最无厘头的地方,既没有出现完整的示例,也没有给人予清晰的感觉,完全就像是凭空造物,更应该放在讲完services之后出现。现在让我们来讲讲angular中的services。
由于angular只能将其能够明白的对象进行组装/连接,所以在能够做DI之前,我们首先需要将要用的对象注册到angular的module中。另外,强调了一个注册的对象不是直接注册对象的实例,而是丢一个创建对象的谱,这个讲的跟传世剑谱似的,暂时没有想到破解的招,得等理解了$injector和$provide之后再来回顾。
angular中可以看作是services的有好几种:values、services、factories、constants、providers
Values
最简单的注册一个对象的方式就是用value()了,而且它注册的事一个预先初始化的对象。下面来看一下推送消息这个例子中的第一个service:
var myMod = angular.module("myMod", []);
myMod.value("notificationsArchive", new NotificationsArchive());
通过上面的代码,我们知道,任何要通过DI机制管理的service都需要有自己唯一的名称。这也是value()中的第一个参数,第二个参数则是创建菜谱的一个函数或是对象。
通过value()这个方法注册的对象不能依赖别的对象。这个方法本身就是用来注册极简单的对象的。
Services
对于推送消息的这个例子中的第二个service,由于它依赖于上面用value()创建的archive-service,所以它不能用value()方法创建,而且它是要将一个依赖于别的对象的构造函数注册为service,所以可以采用service()的方式:
// myMode is the module we created above
myMod.service("notificationsService", NotificationsService);
//NotificationsService is a constructor function
var NotificationsService = function (notificationsArchive) {
this.notificationsArchive = notificationsArchive;
}
明眼人一眼就看到了用value()和service()时的第二个参数发生了不同。那就是后者的第二个参数怎么不用new关键字了?因为这个service使用了angular的DI机制来处理依赖,所以它不用考虑依赖的初始化也可以接受archive-service了。
在实践中,service()方法并不常用,只有在要用来注册已经存在的构造函数时它才显得比较便利。
另外,需要注意:service这个词有两个含义:一个是指service()方法,一个是泛指包括所有通过DI机制管理的angular提供的公用服务。
Factories
跟service()方法相比,factory()方法显得更加灵活,因为我们不单单可以注册预先已经存在的构造函数了,而且可以注册任何用来创建对象的函数(object-creating function),看下面的例子:
// 采用factory方法实现和上一个例子一样的service
myMod.factory("notificationsService", function(notificationsArchive) {
var MAX_LEN = 10;
var notifications = [];
return {
push: function (notification) {
var notificationToArchive;
var newLen = notifications.unshift(notification);
// push方法可以依赖闭包作用域
if (newLen > MAX_LEN) {
notificationToArchive = this.notifications.pop();
notificationsArchive.archive(notificationToArchive);
}
},
// notificationsService的别的方法
}
})
如上面代码所示,factory()方法有以下几个特点:
- 会返回一个对象,它可以是任何有效的js对象,包括函数对象
- 它是angular中最常见的把对象融入到DI机制的方法
- 非常灵活,第二个参数,即创建对象的函数可以非常灵活
- 因为
factory()也是普通的js函数,所以我们可以在其里面使用一个词法作用域(lexical scope)来模拟私有对象,这样我们就可以将service的具体实现细节隐藏起来,只把service的方法暴露出去提供用户使用
Constants
上面经过factory()出厂的notificationsService已经很好用了:
- 和协作对象(notificationsArchive)解耦
- 隐藏了自己的私有状态和具体的实现细节
当然,还有一点可以做的更好,那就是其中的配置参数,如MAX_LEN等都是硬编码在其中的常数。angular对于这个,也有解救的办法,那就是把这些常数当作协作对象注册到module之下,然后就可以通过DI机制供别的对象使用了。这主要要归功于constant()方法:
// 注册一个常数service
myMod.constant("MAX_LEN", 10);
// 修改factory service中的第二个参数
function (notificationsArchive, MAX_LEN) {
...
// creation logic doesn't change
// var MAX_LEN = 10;这一行硬编码就可以去掉了
}
constants常常用来存储一些配置相关的service,可以方便用户按照自己的意愿进行配置。
Providers
provider()方法是更具有一般性的,相比于之前的几个方法都有各自的用途,它是可以做到上面所有方法想要创建的service,可以理解为一个超集。下面是notificationsService用provider()来提供的一个示例:
myMod.provider("notificationsService", function() {
var config = {
maxLen : 10
};
var notifications = [];
return {
setMaxLen : function(maxLen) {
config.maxLen = maxLen || config.maxLen;
}
$get: function(notificationsArchive) {
return {
push : function(notification) {
...
if (newLen > config.maxLen) {
...
}
},
// notificationsService的别的方法
}
}
}
})
provider()方法是一个必须返回包含$get属性的对象的方法。而$get属性又是一个factory方法,返回一个factory service的实例。我们可以把providers看作是一个将factory()方法内置在自己内部的$get属性中的对象。- 另外,
provider()相当于把配置相关的选项也集成在自己体内,可以在factory()方法启动之前先做好相关的配置。
angular的modules的生命周期
前面两节讲了angular中的module以及在其下面注册了各种各样的services,最后可以通过DI机制将所有协作对象整合到一块,成为一个非常灵活的app。这一切都是发生在modules命名空间之下的。那么modules的整个生命周期是怎么样的呢?
从上面services中的最后一个provider()方法的实现我们可以看到angular为了更好的支持providers,将modules的生命周期划成两段:
- 配置阶段:所有的“配方”(食谱)被集齐并进行配置的阶段
- 运行阶段:完成所有的初始化生产出合格的对象实例的阶段
让我们具体来看看这两个阶段具体是干啥的。
配置阶段
providers只能在配置阶段进行配置。你可以这么想把,你总不可能把煮好的东西再拿去换个“食谱”再重新弄吧?只能是把“食谱”搞定好,才开始炒菜呀啥的,然后搞定。除了上一节中讲的可以在provider()之中进行配置,还可以利用单独的一个用于对各种各样的services进行配置管理的API(config()):
myMod.config(function(notificationsServiceProvider) {
notificationsServiceProvider.setMaxLen(5);
})
从上面可以看到,对于该API就是给一个函数对象作为参数进行配置,而函数对象中的参数则是服务名+服务类型名,以服务类型为后缀结尾,以示你是要对哪一种服务进行配置,而在函数对象的逻辑中,则可以调用具体的服务里面的已有的可对外暴露的配置相关的方法,如上面例子中的setMaxLen()就是属于provider()中的。
最后提示下,通过config()方法进行配置,是我们在真正进入初始化要产生对象实例之前最后一次机会对具体要产生对象的构造函数进行怎么变化的最后机会。
运行阶段
run()方法允许我们告诉angular,我想让我的app在启动时跑起来哪些东西。你可以把它当作是C语言中的main()函数,但是又不尽相同,因为angular允许我们可以有多个配置和运行块,也就是说有多个函数入口点。
假设我们需要在app运行时显示程序运行倒计时,我们可以这样做:
angular.module("upTimeApp", []).run(function($rootScope) {
$rootScope.appStarted = new Date();
})
// 在模版中使用上面注册的属性
Application started at: { {appStarted} }
上面这个例子其实我是没有看出有哪里解释到了run(),反正我们知道这个方法会让一个service跑起来,之后找到更好的例子再补上。
不同的服务注册方法在两阶段中的差异
| 方法 | 注册了啥 | 配置阶段可注入否 | 运行阶段可注入否 |
|---|---|---|---|
| Constant | 常数值 | 可以 | 可以 |
| Value | 变量值 | 不能 | 可以 |
| Service | 构造函数创建的新对象 | 不能 | 可以 |
| Factory | factory函数返回的新对象 | 不能 | 可以 |
| Provider | $get函数返回的新对象 | 可以 | 不能 |
modules间的依赖
如果说协作对象之间的相互依赖(object dependencies)是angular中的intra依赖体系,那么modules之间的依赖就是属于inter依赖体系。modules之间的依赖粒度更大,但依赖程度视具体的模块之间的功能决定。
你可以把单个的module理解成是许多个service组合起来的一个小库,暂且称它为service library(服务集合仓库)。那么一个module,可能需要依赖别的仓库集,也可能不需要。以我们之前推送消息的例子来看,我们可以将notifications和archive剥离出来,让它们单独成为module(当然这个有点小题大做,只为了展示效果而已):
angular.module("application", ["notifications", "archive"])
像上面的这种方式,每个service或是每个services集合都能够成为可重用的实体,也就是一个module。然后有一个最顶层级(应用层级的)的module,在上面的例子中就是application了,它可以声明自己都依赖于哪些别的模块。当然,别的模块也可以声明自己依赖于哪些别的模块或是它自己的子模块,这样,模块也就构成了一个父子级别的层级架构。
综上所述,我们在处理angular的模块时,我们需要考虑两个独立却有有联系的分层:
- modules hierarchy(模块层)
- services hierarchy(服务层)
有了这样两个分层结构,就会出现很多有趣的问题:
- 定义在模块
modA下的服务serviceA能否依赖于定义在模块modB下的服务? - 有父子两个模块,
modP是modC的父模块,那么在定义在子模块modC下的服务能否依赖于定义在父模块modP中的服务?还是说只能依赖于同级子模块下的服务? - 是否能够定义只对某个特定模块可见的私有服务?
- 在不同模块下的某些服务可以有相同的名称么?
services及其跨模块间的可见性
子级模块中的services是可以被父级模块中的services访问到并引入作为依赖的。看下面一段代码:
// 应用级(父级)模块:app
angular.module("app", ["engines"])
.factory("car", function ($log, dieselEngine) {
return {
start: function() {
$log.info("Starting " + dieselEngine.type);
}
};
});
//子级模块:engines
angular.module("engines", [])
.factory("dieselEngine", function() {
return {
type: "diesel"
};
});
由于app模块声明了自己依赖engines模块,所以app模块下的car服务的第二个参数(实例化)可以注入dieselEngine的一个实例。
另外同级模块之间的服务,也是相互可见的。把上面的代码做一个小小的改动:把car服务剥离出来成为一个单独的模块,然后改写一下模块层的依赖,如下:
angular.module("app", ["engines", "cars"])
angular.module("engines", [])
.factory("dieselEngine", function() {
return {
type: "diesel"
};
});
angular.module("cars", [])
.factory("car", function($log, dieselEngine) {
return {
start: function() {
$log.info("Starting " + dieselEngine.type);
}
};
});
综上所述,一句话:定义在一个模块中的服务,对于别的模块,总是可见的。模块的分层并不影响服务之间的通讯和可访问性。这样的分层只是为了在逻辑上更为直观一些,在代码书写上更为清晰一些罢了。一个angular应用启动的时候,angular就把它所包含的所有服务(无论是模块内的还是模块间的)都整合起来到全局的命名空间下了。
如上所述,既然最后是整合到一个全局的命名空间,那么显然,不同模块之间的服务名是不能相同的,那样选择级别更高(优先级)的服务会重写另外一个同名服务的内容。看以下的例子:
angular.module("app", ["engines", "cars"])
.controller("AppCtrl", function($scope, car) {
car.start();
})
// engines模块
angular.module("engines", [])
.factory("dieselEngine", function() {
return {
type: "diesel"
};
});
// cars模块
angular.module("cars", [])
.factory("car", function($log, dieselEngine) {
return {
start: function() {
$log.info("Starting " + dieselEngine.type);
}
};
})
// 直接在cars模块下又多添加了一个dieselEngine服务
.factory("dieselEngine", function() {
return {
type: "custom diesel"
}
});
上面的代码跑起来的过程是这样的:
- 首先,
app模块启动,加载engines和cars两个模块 - 然后,在应用级模块
app下注册了一个控制器,用来初始化整个应用程序的数据模型及操作逻辑 - 之后,进入控制器,控制器用第二个参数(构造函数)开始初始化对象,这时候控制器加载
cars模块下的car服务,进入代码内部,启动car服务,调用其start()方法 - 接着,
start()方法的调用就需要执行dieselEngine服务取到相应的type,那这时候angular就需要决定是去取哪个dieselEngine服务了,因为在同级cars模块下有这个服务(属于模块内的调用),在跨模块间的engines模块也有 - 最后,考虑到模块内的服务调用优先级肯定要高,所以自然最后在日志中log出来的内容是:custom diesel
最后,在目前的angular版本下,是不支持能够定义只对某个特定模块可见的私有服务。至此,之前的4个问题陆陆续续也就解答完毕了,我在原书的基础上写了自己的理解,自己去对照哪个问题在哪里解决吧,应该不难找的。
至于这时候肯定会有人问啦,为什么要在angular中使用modules?不要问我,接着看下去,书本的第二章。这也算是吊胃口的设计吧。我能说的就是分成各个小的单独的子模块,你不觉得逻辑更清晰么?而且对单元测试有益。虽然最后angular还是把所有的modules整合到一个大包里。
angular与其他框架
毫无疑问,一出新的MV*的框架,所以人都会想着去做比较,到底适不适合我用,适不适合我们项目呀,诸如此类的问题,但是,真正最后能够决定你在项目中采用什么框架的因素是多元的:团队经验,应用类型,项目规模,个人喜好等等。
首先这边有个链TodoMVC,你可以去看看同样的一个小demo完成Todo-list的例子,用不同的MVC框架做会是怎么样,你可以去比较比较不同的代码语法、大小和可读性。
至于angular框架的好处和优势,待我用过之后再回来总结吧。
To be added ...
angular和jQuery
实话讲,一个是框架,一个是库,是我唯一接触过的两个东西,我非常想对这两者做一些比较,现在能做的比较只能是比较粗浅层面的,所以暂时按下不表。
这里推荐一篇文章:Think in AngularJS,文章比较详细地对比了二者。算比较深入了。
总结
我其实很讨厌每到一章就要来个总结,技术书你有毛写总结的,多增加一些版面赚取版面费么亲?纸很贵的好吧,以后注意了。咳咳。
Ch.2 Building and Testing
这章就点出接下来的所有章节就是围绕要开发一个支持SCRUM敏捷软件开发方法的项目管理工具。这个工具的目标是帮助我们进行angular的API及相关术语的展示,以及一些其他内容如与后台交互,导航管理,安全等等。而这一章的主要内容是介绍这个示例app的问题域(problem domain)以及要用到的技术栈(technical stack)。
每个项目开始于初始的几个决定:包括文件组织策略,开发采用什么样的系统(框架),以及基本的工作流。另外,自动化测试对于一个项目的重要性不言而喻。
所以,在这一章里,我们将要学到:
- 示例app所属的问题域及要用到的技术栈
- 开发angular项目(web-app)要用到的系统以及相关工具及工作流
- 推荐的文件组织及目录管理方式
- 自动测试实践(考虑到测试属于未涉及领域,我可能会暂缓这部分的翻译)
示例应用介绍
示例应用在GitHub上的托管地址,可以先抓一份下来看看目录结构。这里顺便说下,个人认为技术选型和文件目录组织同等级别,技术路线确定后马上要考虑的就是文件目录组织形式了。
问题域
利用SCRUM方法去管理项目。当然,我们的这个sample是属于小型的项目,不会说去满足SCRUM的所有方面。以下是我们即将完成的app的屏幕截图:

从上面的截图我们可以看到这个sample-app是一个典型的CRUD的web应用,它包括以下几个功能:
- 获取、展示及编辑从一个永久存储的数据库里传来的数据
- 认证及授权
- 相对简单的导航,包括应该有的UI元素,如菜单栏,提示信息等
技术栈
这里我们选用的各项技术都是基于js的,这样才能使其融成一个整体。
持久性存储
选用基于文档的存储策略的MongoDB数据库,它是一种所谓的最近很火的NoSQL存储。它很好地契合了js开发环境下的存储需求:
- 文档是被存储于JSON风格的数据格式中
- 查询和数据操作可以通过js及相关API完成
- 可以将数据以REST的形式提供给客户端
网上能够找到的基于云存储策略的数据库托管服务,而且要是免费的,推荐MongoLab,易上手,而且小于500MB以下的空间是免费提供的。这对于我们这个sample是足够了。MongoLab有一个不能忽略的优势:它是通过一组REST接口来暴露数据库的。我们将会使用这一组API来看看angular是如何与提供REST服务的节点进行通讯的。要使用这个服务,只需到网上注册一下,so easy。
服务器端开发环境
- 简单情景:如果只是简单的小项目,你完全可以用MongoLab提供的REST的API让angular直接从托管在MongoLab上的数据库上抓数据,没有任何问题。
- 复杂情景:但是如果项目规模大了,需要考虑安全性等问题时,上面的简单粗暴直接的方式显然是不行的。所以,在实践中,angular写的UI常常是通过与某种后台通信,然后通过它去取MongoLab上的数据。这就是所谓的“中间件”可以提供的功能:安全服务(认证)及判定权限(授权)。
显然,我们的sample-app虽然简单,但是也需要有一个简单粗暴的后台,这里我们用node.js作为我们的后台解决方案。node.js不是我们这本书要讲的内容,我们只需要了解基础的以及关于npm的一些内容即可,因为关键是我们项目中不会直接去用原生的node.js去写一个server,我们会用到相关的node.js的库去搭建我们的服务器端(所谓的后台)的开发环境,典型的node.js库有:
这一节其实是为我们开始学习后端提供一个引子,尤其是我自己,所以重点mark。
第三方js类库
angular完全可以独自使用,但是如果有现成的轮子呀,车轱辘,那干嘛还需要再用angular再闭门造一次车呢?对吧?所以,项目中我们会教你如何使用在angular中去用jQuery,underscore.js等第三方类库,着重是jQuery。
css库
用css类库来将我们的UI进行样式化会省去我们裸写一大堆css代码的麻烦,当然,angular并没有强行指定需要使用具体哪个css类库。项目中,我们会使用Twitter Bootstrap这个类库。同时,我们引进了LESS这个css预处理器。
开发体系及工作流
js从之前的玩具似的语言,到现在亦可开发大型的web-app,不断增长的复杂度也就意味着代码量也慢慢增加,那么对于js为主体的文件管理,我们不能再像以前一样,幻想在HTML文件中只包含进一个js文件就可以搞定一切了。这样,我们就需要一个build system,怎么样来翻译这个词好呢,我想是用“开发体系”(暂定)。这就包括js和css文件在能够部署到产品服务器之前的一切检测、变换(如压缩)等。以下列举一些需要做到的变换:
- 用
jslint检测js代码的兼容性 - 测试工具集的检测
- 用LESS对css进行预处理
- 文件的整合及压缩
- 文档更新
除了以上列出的几条,整个app在能够部署之前,要经历的大小琐事还真是多,所以不得不有一套开发体系来保障这个开发到部署的过程的连续性和有效性,如果能够让这些需要每次都去调来调去的繁琐的任务自动化部署实现,那就thank-god了,幸运的是,这就是“开发体系”要做的事。
开发体系原则
这一部分得是架构师水平的人才能理解,写出来的,所以这里面就不敢造次,不敢翻,当然,对学习开发也没太大影响,关键是要积累代码量,然后慢慢领悟,现在看几条大原则,我们也不懂如何结合实际,所以不浪费这个时间翻这一段。市面上很多翻书的,也是渣渣,但是特别爱翻这种大道理,大原则性的东西,但是根本实践上让菜鸟们怎么去着手,怎么去apply,无从下手,还是作罢。当然,很多淘宝的牛人翻的动物书还是很犀利的,但也不乏烂货。(ps:我自己现在翻的也很烂,自己将就着先看。)
- Automate everything(废话,谁都想呀,但你倒是告诉我实际点的东西呀,别整些大词汇,没用的)
- Fail fast, fail clean
- Different workflows, different commands
- Build scripts are code too
开发工具
这里选择的开发工具链是OS无关的(operating system agnostic),你可以在任何主流的OS上跑这个sample-app。虽然我们针对这个sample选择了以下这样的开发工具链,但是对于别的项目,当然可以采用不同的工具。但是这个工具链是推荐的。
- Grunt.js:使用Gruntjs来搭建一个前端项目,然后使用grunt合并,压缩JS文件(具体怎么用还得更深入学习)
- 测试工具集及类库
- Jasmine
- Karma
关于开发工具就翻这么多吧,具体的只要用关键词grunt构建前端项目就一大堆结果了。
文件目录组织
刚刚clone下来了sample-app的项目,配了下MongoDB,分别用npm在client和server端把需要的依赖装上之后,用node把server跑起来,然后localhost可以用MongoDB暴露的用户登录,感觉很开森,虽然还不晓得怎么个过程,但至少知道了我们访问网站时的一个过程和实际上后面的实现过程完全不同:
- 用户表面上看到的过程:从前端到后台,再从后台去DB取数据的过程。
- 背后实现的过程:先有一个数据库,然后给数据库创建可以访问的用户,然后围绕这个DB进行server端的代码编写,然后跑起server来支持前端。
接下来就让我们来扒开它的衣服看看里面都有什么。
文件目录结构
在最顶层,如下图所示,整个项目包括两个文件夹还有其他一些附加物:
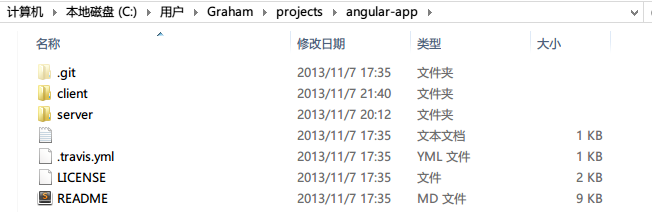
- client文件夹:包括所有的客户端angular应用
- server文件夹:包括一个基本的基于express实现的webserver来支持整个前端
- README:可以说是标配了,说明这个项目怎么跑的一个说明说
- LICENSE:说明这个项目的营业执照,你懂的
再往里一层,如下图所示,整个client文件夹包括以下结构:
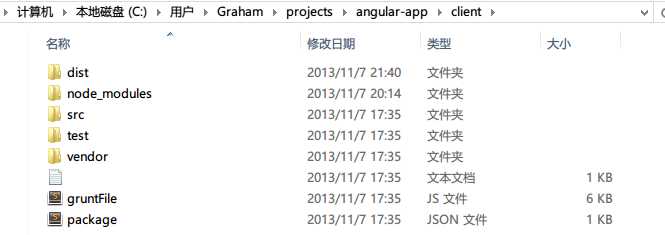
- src文件夹:包括整个app的所有源代码
- test文件夹:包括整个app中协同的测试代码
- vendor文件夹:包括所有第三方依赖(这里的依赖和后面的node_modules不同,这里的是js类库的依赖,如angular-ui之类的)
- build文件夹:包括所有的编译脚本(但是最新版本中已经没有这个文件夹了,目前尚不知整合到哪里了)
- dist文件夹:包含了整个项目的编译结果(打包结果),可以作为发布版本(这里所说的编译和传统的不同,因为大家知道js是解释性语言,所以这里编译只是借用这个词,强调的是把所有js,css等文件整合压缩等的最后过程,可以理解为打包)
- gruntFile.js:这个可能就是吸收了原来的build文件夹和原来的grunt.js之后整合的用来做打包操作的命令执行脚本
- package.js:包含了所有npm(node包依赖管理工具)要安装打包要依赖的工具时的所有工具集
- node_modules文件夹:包含了
npm install之后根据package.js列的清单安装的所有打包工具依赖集
现在让我们再进一层,进到src文件夹探个究竟:
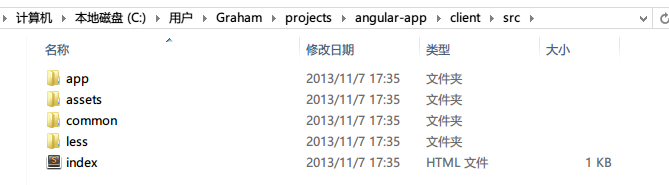
- index.html:这个是整个应用程序的入口点了
- app文件夹和common文件夹:包括与angular相关的代码
- assets和less文件夹:包括与angular无关的内容;assets主要放图片等资源,而less主要放的是less预处理器用到的变量。需要注意的是,为推特的bootstrap样式而准备的LESS模版是放在了上一层的vendor文件夹(即第三方依赖)下
src文件夹里面的东西,大部分是脚本和HTML,那么怎么来组织这么多的文件呢,按它们的特点来,还是按结构层次来,还是按文件类型来呢?这里面在src文件夹里的各个文件夹,我们采取混合组织的一种策略,主要先把为了相同/相似功能服务的文件组织到一块,来来来,让我们打开app文件夹看看:
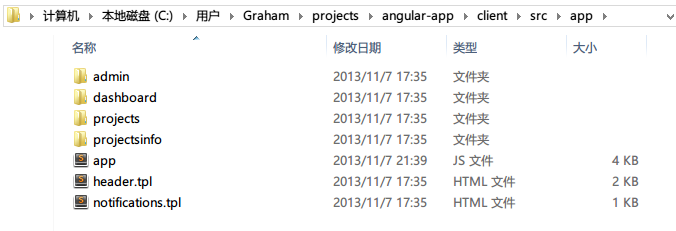
- admin文件夹:主要负责admin账户的逻辑
- dashboard文件夹:负责产生的项目管理面板的逻辑
- projects文件夹:负责项目的所有相关逻辑
- projectsinfo文件夹:负责项目缩略信息的逻辑
- app.js:整个项目angular部分的模块划分及路由选择,项目总的js逻辑
- header.tpl.html:项目header模版
- notifications.tpl.html:项目通知系统模版
接着是common文件夹,主要是存放angular应用的别的通用部件:
- directives文件夹:包括所有的指令
- resources文件夹:目前还不晓得干嘛的,全部是js文件
- security文件夹:用于登录及认证等机制,与MongoDB有通信
- services文件夹:用于存放公用服务
至于src文件夹下的另外两个子文件夹:assets和less文件夹,里面就是放图片资源和less变量,就不用细看。这样,看完了src下的一层又一层,跟洋葱似的,接着来看看和src同级的test文件夹都有什么好料:
- config文件夹:对于配置的测试
- unit文件夹:做单元测试的
- vendor文件夹:这个命名个人感觉不好
紧接着是vendor文件夹,这里就不po截图了,简单来看看在开发时(写js代码时)都需要调用哪些第三方的API:
- angular库:包括angular.js和angular-route.js
- angular-ui库:存放为bootstrap准备的angular-ui
- bootstrap库:存放LESS模版
- jquery库:jquery.js
- mongolab库:存放mongoDB的API
而最后看一下dist文件夹,它是最后用grunt工具编译(打包)之后生成的可以用来发布的版本,也就是说用node server.js跑起来后,通过localhost访问到的就是最后的这个文件夹里面的index.html为入口点的angular-app。
罗马非一日之功也
上面描述了一个很理想的目录结构,但是非大牛者,不能为也,不可能像本小菜这样的能够一下子就在项目还没开始的时候把目录结构统统给搞好了,然后好吧,你们就往里面填东西得了,不是这样子的,本书作者也阐述了这一观点。一个项目总是开始于一个很简单的结构的,然后一小步一小步往最后的愿景去靠。
文件命名惯例
对于那么多文件夹那么多目录下的那么多文件,文件命名是一个大的挑战,最好在总体上有个一致性,可以试着考虑使用二级后缀。如模版文件可以用.tpl.html为结尾。
angular中的module和文件对应
整个应用现在已经被很有序地组织好了,现在是时候看看各个文件里的具体内容,他们和angular的模块式怎么关联的。
一个文件,一个模块
一般来讲modules和files的对应关系可能会有如下三种:
- A:多个angular模块在一个js文件中
- B:一个angular模块散落在多个js文件中定义
- C:一个angular模块严格对应一个js文件
理论上和实际上来看,无疑C选项是最好的,它的好处太多了,当然还包括在单元测试中可以单独加载每个模块,最多还能容忍的是放少部分几个有相似功能/性质的模块在同一个文件中,如几个模块构成一个总功能(或是模版中的一个小组件),但是绝对不允许把一个模块分布在多个文件中定义。
模块内部呢?
一个文件里面声明好一个模块之后,那就可以往里头注册“菜谱”了,也就是各种各样的providers了,至于注册哪一种,当然是看要炒什么菜,就放什么样的“谱”了。
往模块中注册多个providers的不同实现语法
定义一个变量用来作为返回的模块实例的引用,然后用这个变量来注册多个providers(或是controllers等),这其实就是利用一个中间变量来作为引用,但是这个方式的缺点很明显:这个变量是作为全局变量暴露在全局名称空间下的,这样我们就不得不采取一些别的补救策略,例如把整个module声明放到闭包里,单独声明一个命名空间之类的。不管怎么,来看看这种方法的实现,如下:
var adminProjects = augular.module("admin-projects", []); // 第一个controller adminProjects.controller("ProjectsListCtrl", function($scope) { // controller logic goes here }); // 第二个controller adminProjects.controller("ProjectsEditCtrl", function($scope) { // controller logic goes here });理想情况下,我们可以直接把这个中间变量省去,如果你看了下面的代码,其实也没有多少优化,
angular.module("admin-projects")重复出现。代码重复大多数情况下都是不好的,比如,如果某天心血来潮要给module换个名字,尼玛,那你慢慢换吧。而且声明模块和引用模块的代码只差了一个[]`的依赖包,很容易让人忽略这之间的细微差别导致别的错误。augular.module("admin-projects", []); angular.module("admin-projects").controller("ProjectsListCtrl", function($scope) { // controller logic goes here }); angular.module("admin-projects").controller("ProjectsEditCtrl", function($scope) { // controller logic goes here });幸运的是,我们有最后一种方法可以解决以上所讲的种种尴尬,链式调用,直接看下下面的代码:
angular.module("admin-projects", []) .controller("ProjectsListCtrl", function($scope) { // controller logic goes here }) .controller("ProjectsEditCtrl", function($scope) { // controller logic goes here }) .factory() .service();
声明配置阶段与运行阶段的语法
第一章中介绍过,启动一个angular应用时是被分成两个阶段,不记得回去巩固去。但是当时没跟大家透露说,每个模块可以有多个配置和运行的代码块,不一定只在一棵树上吊死呀,骚年。
angular支持两种不同的声明配置代码块(同时运行代码块也适用)的方式:
作为
angular.module()的第三个参数进行配置,这样子的配置函数只能注册一个配置块,而且由于多了第三个参数,这让整个module的声明看起来非常冗杂。angular.module("admin-projects", [], function() { // configuration logic goes here })第二种方式是通过在返回的module实例后通过链式调用串上去多个配置块:
angular.module("admin-projects", []) .config(function() { // config block 1 }) .config(function() { // config block 2 });
angular-app目录组织结构
最后,让我们来概览一下angular-app的整个项目结构吧。
angular-app
client -- 应用前端代码文件夹
src -- 项目主要业务逻辑的js和html代码都在这里
app -- 项目特定页面的html和js放在这里
admin -- 管理模块逻辑代码
projects -- 项目管理逻辑的js代码
users -- 用户管理逻辑的js代码
admin.js -- 声明整个项目的admin模块,依赖于上面两个模块
dashboard -- dashboard模块
dashboard.js -- 模块声明
dashboard.tpl.html -- 模块模版
projects -- projects模块
projects.js -- 模块声明
projects-list.tpl.html --
sprints -- sprints模块
sprints.js -- 模块声明
sprints-list.tpl.html --
sprints-edit.tpl.html --
tasks -- tasks模块
tasks.js -- 模块声明
tasks-list.tpl.html --
tasks-edit.tpl.html --
projectsinfo -- projectsinfo模块
projectsinfo.js -- 模块声明
list.tpl.html --
app.js -- 依赖于以上声明的那么多模块,作为唯一往外暴露的入口点
header.tpl.html --
notification.tpl.html --
assets -- 存放项目所用到的资源
img -- 图片资源
common -- 项目用到的脚本
directives -- 指令集
gravatar.js --
modal.js --
crud --
crud.js --
crudButton.js --
edit.js --
services -- 服务集
breadcrumbs.js --
crud.js --
crudRouteProvider.js --
exceptionHandler.js --
httpRequestTracker.js --
i18nNotification.js --
localizedMessages.js --
notifications.js --
resources -- 资源集
backlog.js --
projects.js --
sprints.js --
tasks.js --
users.js --
security -- 安全集
login -- 登录模块
form.tpl.html --
login.js --
LoginFormController.js --
toolbar.js --
toolbar.tpl.html --
authorization.js --
index.js --
interceptor.js --
retryQueue.js --
security.js --
less -- 存放less预处理器的变量
stylesheet.less --
variables.less --
index.html -- 应用唯一入口
test -- 测试代码
config --
unit --
vendor --
vendor -- 第三方依赖
angular --
angular-ui --
bootstrap --
jquery --
mongolab --
node_modules -- npm安装后出现的文件夹(开发的依赖包)
grunt等 --
dist -- 打包后产生的文件夹,可以用作部署
// 一堆打包好的html和js --
gruntFile.js -- 打包用的grunt配置
package.json -- npm会根据这里面的列表安装开发依赖包
server -- 服务器端代码
cert -- 证书相关文件
lib -- 第三方类库
routes -- 页面切换
initDB.js -- 初始化MongoDB
mongo-proxy.js --
mongo-strategy.js --
projectJSON.js --
security.js --
xsrf.js --
test -- 测试相关
mongo-initdb.js --
mongo-proxy.js --
mongo-strategy.js --
security.js --
node_modules -- npm安装后出现的文件夹
express --
grunt --
passport --
open --
rewire --
config.js --
gruntFile.js --
initDB.js --
package.json --
server.js --
LICENSE -- MIT认证
README.md -- 项目指南
自动化单元测试
前面讲了一堆废话,总结起来就是:我们是人,不是神,会出错,要测试。而这其中自动化测试的实践在敏捷开发中尤其流行。而测试主要就讲两种:单元测试;端到端测试。
单元测试是我们对付程序bug的第一道防线。它专注于小块的代码,经常是独立的模块或者对象、类等。单元测试确保我们相对底层的结构的正确性,而且我们所写的函数、代码能够产生我们预期的效果。单元测试有五个好处,但是你Y我现在还没用过,让我直翻我必然不干,所以先占个位吧,后面弄懂了再来翻(当然有可能直接给忘了):
- 及早发现问题
- 能够理清代码思路
- 简单
- 测试驱动开发
- test可以作为文档,我们可以看到一个方法是怎么被调用的,它的参数呀之类的
虽然单元测试很好,但是它不能捕获所有的问题,这时候就需要相对高一层的:端到端测试了。
接下来两小节单独讲测试,目前只好先忽略跳过了。